杏彩体育世界杯中国官网首页 VeRL-Omni: 面向扩散和全模态生成模子的通用RL后张望框架
发布日期:2026-05-27 18:17 点击次数:51

VeRL-Omni 是一个面向多模态生成模子的通用 RL 后张望框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。掩饰扩散 transformer(Qwen-Image)、搀和 AR-DiT(Qwen-Omni)、颐养相识 + 生成(BAGEL、HunyuanImage-3.0)等架构。
多模态 rollout 走 vLLM-Omni 的异步高综合 serving,VLM-as-judge / OCR 奖励模子走 vLLM 推理,并与 rollout、张望 overlap。Qwen-Image OCR FlowGRPO 演示中,把奖励模子放到孤立 GPU 可将每步 wall-clock 时刻裁减约 14%。
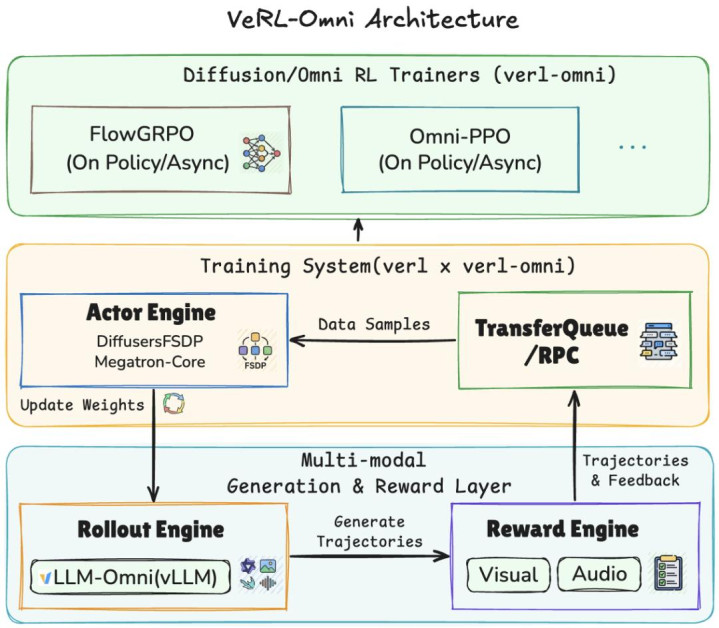
VeRL-Omni 架构
代码: github.com/verl-project/verl-omni
文档: verl-omni.readthedocs.io
vLLM 官方博客:vllm.ai/blog/verl-omni
为什么需要 VeRL-Omni
RL 如故成为把大型生成模子对都到东说念主类偏好与下贱任务奖励的有劲时刻。畴前一年 LLM 的 RL 张望栈赶紧演进,但多模态生成 RL—— 掩饰图像 / 视频 / 音频相识与生成的扩散和全模态模子 —— 还有几个枢纽缺口:
扩散与全模态扩张:把 verl 的天真性和性能延迟到多模态、非自总结 RL 张望的宇宙,包括扩散 transformer 骨干(Qwen-Image)、搀和 AR-DiT 架构(Qwen-Omni)、颐养相识 + 生成模子(BAGEL、HunyuanImage-3.0);
异构 rollout 活水线:Rollout 是邻接 latent 空间里的去噪轨迹,而不是 token 序列;单次 rollout 还可能调用多个异构模子组件、走多阶段活水线(text encoder → DiT → VAE);
复杂的负载改变:多模态 RL 张望的奖励函数自己即是多模态模子(VLM judge、OCR scorer 等),多模态生成 rollout 的峰值显存又比文本生成高得多,把这些使命流编排好并不简便。
枢纽特色
高效的多模态 rollout: 集成 vLLM-Omni 的异步高综合多模态生成 serving,精度与 diffusers 抓平。VeRL-Omni 与 vLLM-Omni 协同,通过 step-wise continuous batching、embedding caching 等抓续优化 rollout 恶果。
天确实奖励引擎: 同期因循基于法律评释注解的奖励与基于模子的奖励(如 VLM-as-judge for OCR)。集成 vLLM 用于高效的 VLM / LLM 奖励模子推理。奖励运筹帷幄与 rollout、张望历程 overlap,裁减端到端延迟。
模块化张望后端: 提供多种 trainer(DiffusersFSDP / Megatron / VeOmni),针对扩散和全模态模子内置优化,便于接入不同并行战略(FSDP / USP / TP)。
世俗的硬件兼容: 同期因循 NVIDIA GPU 和昇腾 NPU,部署可在多种硬件后端之间天显露换。
端到端张望 recipe 与基准: 提供参考性能抛弃;收获于上述特色,张望综合不错作念得很高。
算法与模子因循
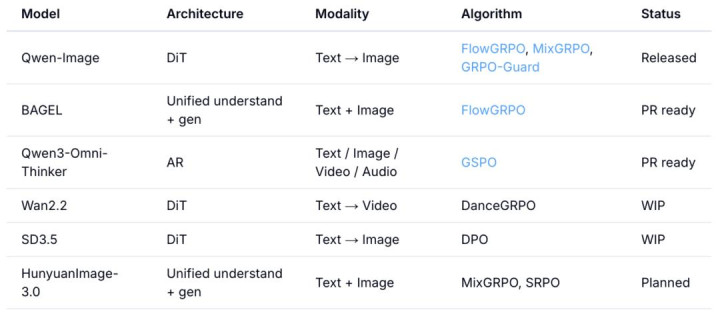
上手指南
装配
详见装配文档:
https://verl-omni.readthedocs.io/en/latest/start/install.html
张望扩散模子
examples 目次(https://github.com/verl-project/verl-omni/tree/main/examples)提供了不同 RL 算法 trainer 的启动剧本,掩饰图像 / 音频 / 视频相识与生成任务。张望性能与抛弃不错通过 wandb 追踪。
Demo:Qwen-Image FlowGRPO 后张望
在 flowgrpo 示例中,团队用 OCR 奖励任务张望 Qwen-Image。奖励模子秉承 Qwen3-VL-8B-Instruct,通过读取生成图像里的渲染笔墨、与数据集 ground truth 比对,对生成图像评分。
flowgrpo 示例:https://github.com/verl-project/verl-omni/tree/main/examples/flowgrpo_trainer
算法回首

FlowGRPO 算法默示
FlowGRPO 默示
FlowGRPO 是面向 flow-matching 模子的在线战略要津。它通过 diffusion policy 模子作念多步 SDE 采样以罢了高效 RL 探索,并秉承基于模子的奖励评估生成质料。
张望历程主要分四步:
Rollout 生成: 扩散 policy 模子生成样本 rollout,杏彩体育世界杯中国官网首页蚁合 log probability 和生成图像的轨迹。
奖励模子打分:奖励模子给每个生成样本打分,用于运筹帷幄 trajectory advantage。
战略优化:用 FlowGRPO CLIP-style loss 更新战略,基于 advantage 优化奖励。
权重同步:如期把 trainer 最新的战略权重同步到 rollout worker,确保生成样本反馈最新战略。
LoRA 微调
NVIDIA H800 GPU 上的张望综合如下:
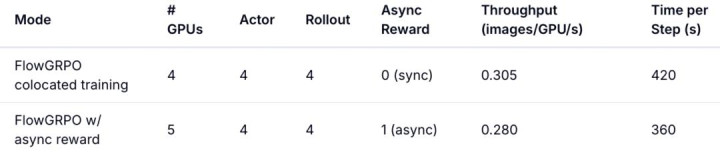
把奖励模子放到孤立 GPU 上,与战略张望 overlap,每步 wall-clock 时刻裁减约 14%。
全模子微调
团队还考证了 non-CFG 全模子 Qwen-Image OCR 张望,在 4×NVIDIA H200 上达到 0.510 images/GPU/s,每步约 250 s。
底下不错看到,仅 120 步张望后,生成图像的笔墨渲染质料已有权贵晋升。
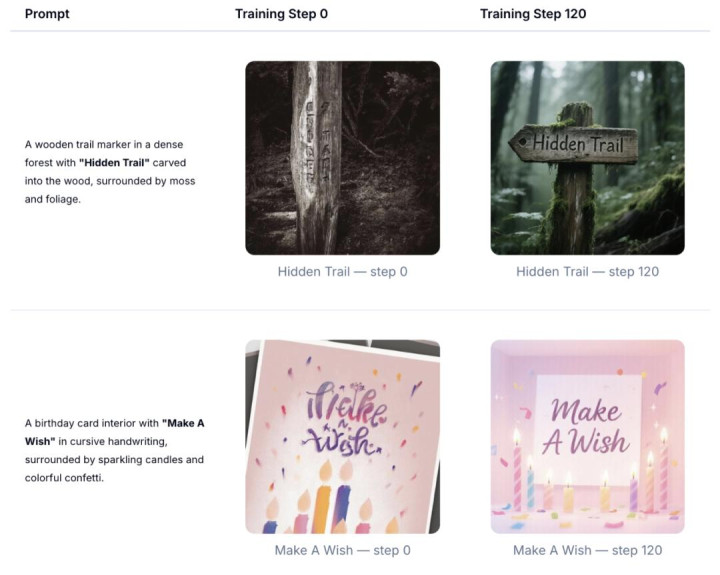
底下是参考张望弧线,critic reward 与 validation reward 都无间矫健。
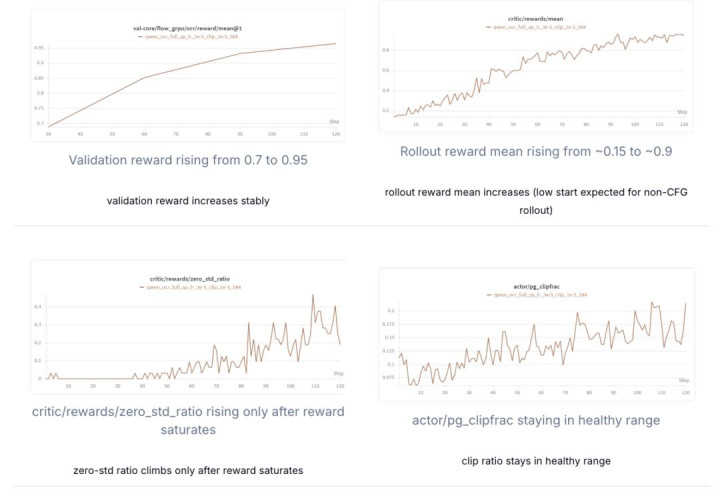
好意思满张望标的说卓识 Training Metrics 文档。
文档地址:https://verl-omni.readthedocs.io/en/latest/start/metrics.html
后续途径图
VeRL-Omni 仍处于活跃迭代的预发布阶段,扩散 RL 中枢栈如故矫健。途径图聚焦在扩张模子 / 算法因循,并链接激动高效多模态 RL 张望的领域。
模子因循扩张: 跟进开源的扩散和全模态模子,掩饰图像 / 视频 / 音频生成任务以及颐养相识 + 生成任务;
算法因循扩张: 抓续集成矫健、先进的 RL 算法(如 DiffusionNFT);
全异步 RL: 在 actor、rollout、reward 之间走端到端异步活水线,超出现时的异步奖励鸿沟,进一步晋升张望综合和 GPU/NPU 期骗率;
与 vLLM-Omni 协同优化: 生成 rollout 在张望时刻中占比很大,将通过更缜密的 vLLM-Omni 集成(并行、量化、batching、改变优化等)链接加快多模态 rollout;
高效全模态 trainer: 在 DiffusersFSDPTrainer 以外,霸术放出更多针对全模态与扩散模子的高度优化 trainer 引擎,基于 Megatron-core 与 VeOmni;
更广的硬件因循: 链接打磨昇腾 NPU 旅途,并通过 hardware plugin 系统接待更多硬件后端。
扩散和全模态 RL 后张望仅仅个开动。VeRL-Omni 团队正在抓续因循更多架构与算法杏彩体育世界杯中国官网首页,接待通盘塑造改日。
 备案号:
备案号: